Skala — liczby, które nie mieszczą się w głowie
| Hyperscaler | CAPEX 2024 | 2025E | Główne wydatki AI |
|---|---|---|---|
| Microsoft (Azure, OpenAI) | ~$80 mld | ~$100 mld | NVDA H100/H200, własne ASIC Maia |
| Google (Cloud, DeepMind) | ~$50 mld | ~$75 mld | NVDA + własne TPU v5/v6 |
| Amazon (AWS, Anthropic) | ~$60 mld | ~$100 mld | NVDA + własne Trainium2, Inferentia |
| Meta | ~$40 mld | ~$60 mld | NVDA H100 (350 000 sztuk!), własne MTIA |
| Apple | ~$10 mld | ~$15 mld | Apple Intelligence, własne silicon |
| Oracle | ~$15 mld | ~$25 mld | NVDA dla OCI (cloud) |
| Tesla, xAI, ByteDance... | ~$30 mld | ~$50 mld | Głównie NVDA |
Dlaczego AI wymaga tylu chipów?
Trenowanie dużego modelu językowego (LLM jak GPT-4 czy Claude) wymaga tysięcy do dziesiątek tysięcy GPU pracujących równolegle przez miesiące. Konkretnie:
- GPT-4 — ~25 000 GPU NVDA A100 przez ~3 miesiące = ~$60 mln kosztów compute.
- GPT-5 / Claude Opus 5 (2025) — ~100 000+ GPU H100/H200, koszt $1-2 mld.
- Inference (codzienne używanie, np. ChatGPT) — wymaga tysięcy GPU non-stop. Inference jest ~10× większym rynkiem niż trening i ten stosunek się powiększa.
Meta zamówiła w 2024 r. 350 000 GPU NVDA H100 dla swoich superklasterów AI — to ekwiwalent $10-15 mld. Microsoft i Azure podobnie. To nie hype — to fizyczne maszyny w serwerowniach.
NVIDIA — kim jest i czemu wygrywa
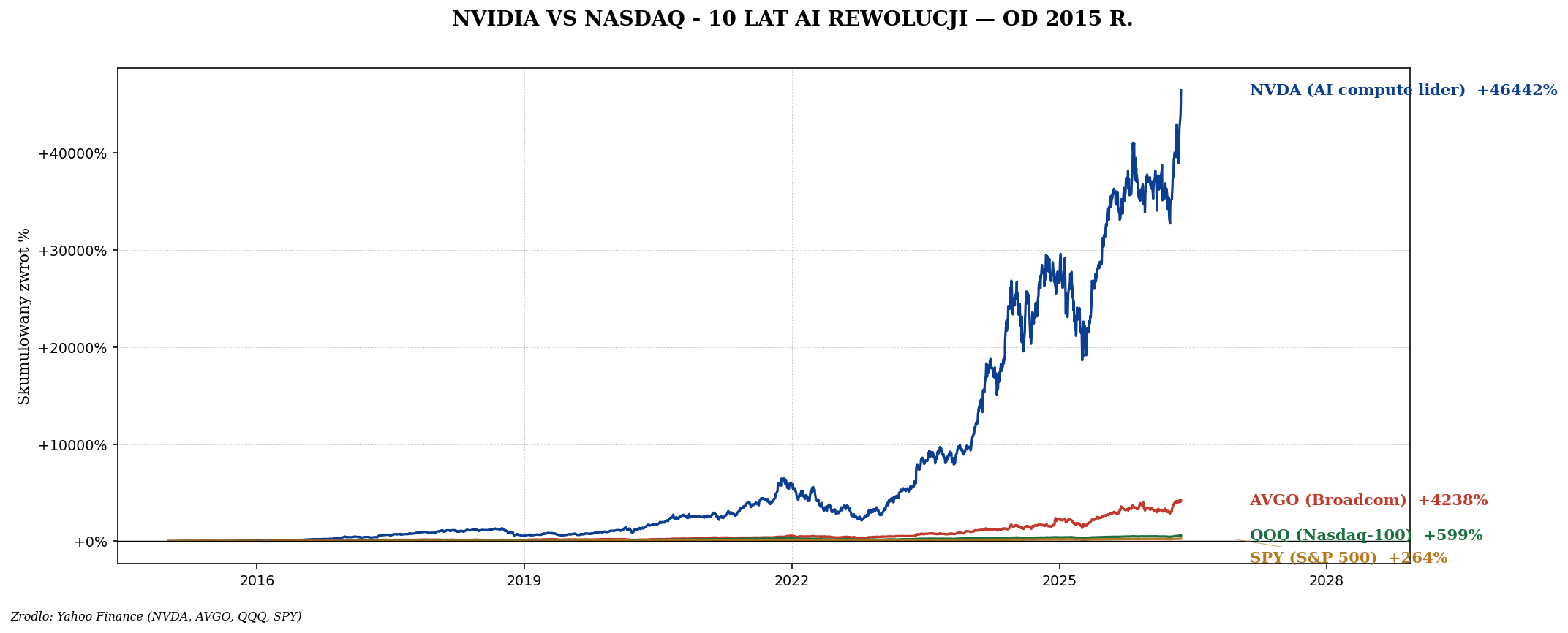
NVIDIA dominuje AI compute ~80-90% rynku z 4 powodów:
- CUDA — proprietary software stack od 2007 r. Każdy AI inżynier go zna, każda biblioteka go używa (PyTorch, TensorFlow). To moat trudniejszy do przeskoczenia niż sam hardware.
- NVLink i InfiniBand — połączenia między GPU. W 2020 r. NVDA kupiła Mellanox za $7 mld — strategia genialna w hindsight. Te połączenia są kluczowe dla "rozproszonego" treningu.
- Roadmap iteracji — Volta (2017) → Ampere (A100, 2020) → Hopper (H100, 2022) → Blackwell (B200, 2024) → Rubin (2026). Każda generacja 2-3× lepsza w AI.
- Ekosystem partnerski — TSMC produkuje, ASML projektuje, SK Hynix dostarcza HBM. NVDA jest centrum, ale buduje wokół siebie współzależności.
HBM — zapomniany bohater AI
GPU bez pamięci jest bezużyteczny. AI workloady wymagają HBM (High Bandwidth Memory) — specjalna pamięć stackowana pionowo, połączona z GPU przez 1024-bit interfejs (vs 64-bit zwykłej DRAM). HBM3e (najnowsza) ma 1,2 TB/s przepustowości — 10× szybciej niż zwykła DDR5.
Tylko trzy firmy potrafią produkować HBM:
| Producent HBM | Udział rynku | Kluczowy klient |
|---|---|---|
| SK Hynix (Korea Płd) | ~50% | NVIDIA (główny dostawca H100/H200/B200) |
| Samsung (Korea Płd) | ~35% | AMD MI300, częściowo NVDA |
| Micron (USA) | ~15% | NVDA H200 (od 2024), rośnie |
CoWoS — wąskie gardło u TSMC
GPU NVDA (np. H100) to nie jeden chip — to "package" z głównym chipem GPU + 6-8 stosami HBM, połączone przez CoWoS (Chip-on-Wafer-on-Substrate). To zaawansowane packaging od TSMC.
W 2023 r. TSMC miał capacity CoWoS ~15 000 wafli/miesiąc. W 2024 r. podwoiło do ~32 000. Plan na 2025-2026: ~80 000. To ograniczenie produkcji NVDA — nie GPU dies (TSMC może wyprodukować więcej), ale packaging. Stąd nazwa "CoWoS bottleneck".
Beneficjenci ery AI compute
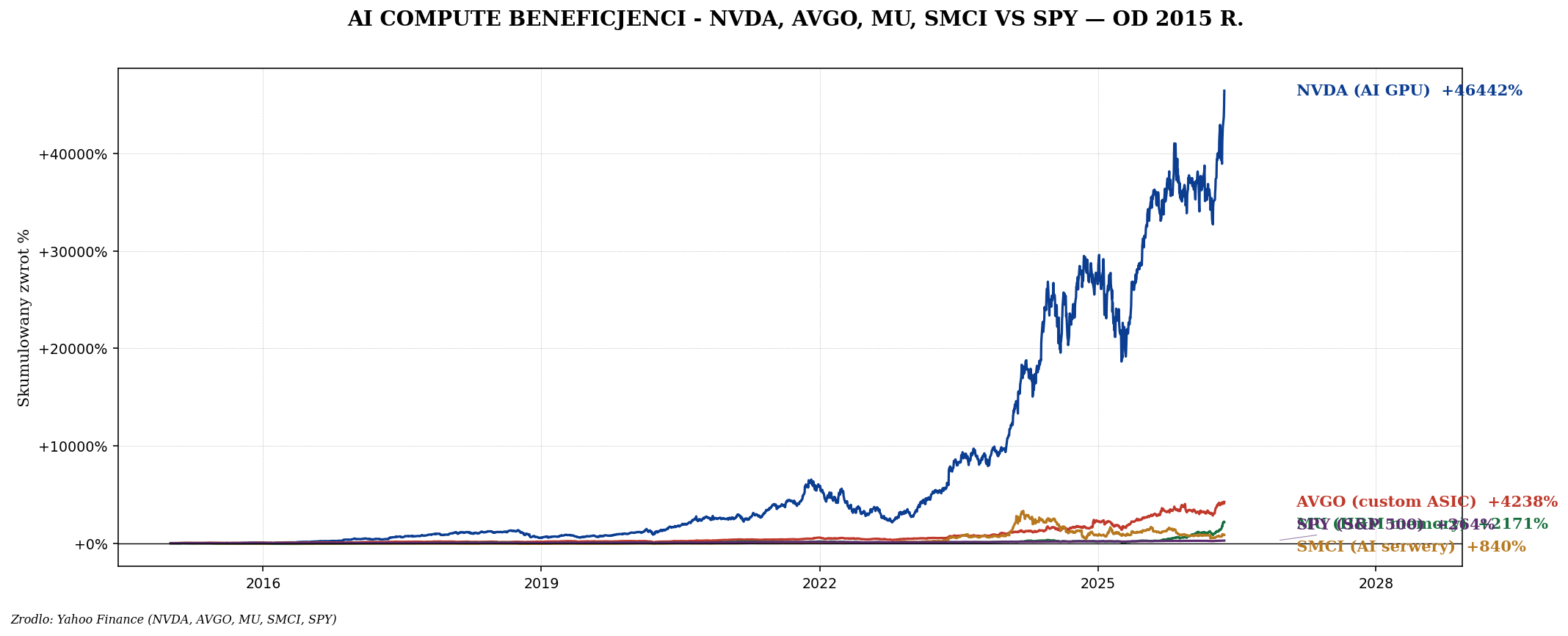
Bezpośredni beneficjenci (Tier 1)
| Spółka | Rola w AI compute | Wzrost 2022-2024 |
|---|---|---|
| NVIDIA (NVDA) | GPU lider (H100, B200) | +800% |
| Broadcom (AVGO) | Custom ASIC (Google TPU, Meta MTIA), networking | +200% |
| TSMC (TSM) | Producent wszystkich AI chipów | +120% |
| SK Hynix (000660.KS) | HBM lider | +150% |
| Micron (MU) | HBM challenger | +100% |
| ASML | EUV maszyny do produkcji | +60% |
Pośredni beneficjenci (Tier 2)
| Spółka | Rola |
|---|---|
| Super Micro Computer (SMCI) | AI serwery z NVDA — eksplozja sprzedaży |
| Arista Networks (ANET) | Networking switche dla AI klastrów |
| Vertiv (VRT) | Cooling, power dla data centers |
| Coherent (COHR) | Optyczne komponenty AI klastrów |
| Cadence (CDNS), Synopsys (SNPS) | EDA software — wszystkie chipy AI tu projektowane |
| Eaton, Schneider Electric | Elektryczna infrastruktura dla data centers |
Tier 3 — energia, woda, ziemia
AI data center pobiera ~50-100 MW (megawatów) — tyle co małe miasto. Energy density rośnie z ~10 kW/rack do ~100 kW/rack. To wymusza:
- Utility companies — NextEra, Duke Energy, Constellation Energy (CEG) wracają do gier. CEG +200% w 2024 r.
- Natural gas — bo solar/wind nie zapewnia 24/7 obciążenia. Renesans gaz jako "baseload" dla AI.
- Nuclear renaissance — Microsoft wynajął Three Mile Island Unit 1 od Constellation. Amazon kupił atomówkę dla swojego DC w Pensylwanii. SMR (Small Modular Reactors) firmy NuScale i Westinghouse na fali.
- Water cooling — Tier 1 GPU klastrów potrzebuje liquid cooling. Sprzedaż Vertiv, Schneider rośnie.
Custom ASIC — zagrożenie dla NVIDII
Hyperscalerzy chcą uniezależnić się od NVIDII (która liczy ~70-80% marży brutto). Projektują własne chipy AI:
| Firma | Chip | Projektant |
|---|---|---|
| TPU v5p, v6e | Sam Google (z pomocą Broadcom) | |
| Amazon | Trainium 2, Inferentia 3 | Annapurna Labs (kupiony przez AWS) |
| Microsoft | Maia 100, Cobalt 100 | Sam MS |
| Meta | MTIA v2 | Sam Meta z Broadcom |
| Tesla | Dojo (chip do treningu autonomii) | Sam Tesla |
Czy to zabije NVIDIĘ? Krótkoterminowo nie — custom ASIC są mniej elastyczne. NVDA dominuje trening modeli LLM. Ale inference (codzienne używanie modeli) coraz częściej przejdzie na ASIC, bo to 50-70% wszystkich kosztów AI.
Tańsze AI = większe zużycie (paradoks Jevonsa)
Krytycy mówią: "DeepSeek pokazał, że można trenować model za 10× mniej $$. AI compute upadnie." Nieprawda. Paradoks Jevonsa: gdy coś staje się tańsze, używamy tego więcej. Tańsze AI = więcej zastosowań = większy popyt na compute.
W 2010 r. trenowanie modelu kosztowało $1000/godzinę. W 2024 r. — $5. Czy zużycie compute spadło? Wzrosło 1000×. Tak samo teraz: efektywniejsze algorytmy + tańsze chipy = jeszcze więcej AI w codziennym życiu. Każdy email, każda strona, każda aplikacja - AI wewnątrz.
Ryzyka ery AI compute
- Bańka wyceny — NVDA przy P/E 35-40, Forward P/E 28. Każda dezelearacja wzrostu = -50%. 2000-2002 też miało "internet to przyszłość" — i było, ale akcje cisco systems do dzisiaj nie wróciły.
- Custom ASIC — w 2-3 lata mogą zmienić strukturę rynku.
- Geopolityka — Tajwan, sankcje na CHN — patrz osobny artykuł.
- Energetyka — jeśli zabraknie prądu, AI się zatrzyma. USA już teraz ma problemy z transformatorami i siecią.
- Regulacje — UE AI Act, USA executive orders. Każda regulacja zwiększa koszty.
- Halucynacje LLM — jeśli AI okaże się "tylko" 80% przydatne (a nie 99%), część przypadków użycia odpadnie. Ale 80% to wciąż gigantyczne.
Jak inwestować w erę AI compute jako Polak
| Strategia | Instrument | Komentarz |
|---|---|---|
| Cała branża | CHIP, SMGB (UCITS chip ETF) | Bezpieczne, dywersyfikacja |
| Mocno NVIDIA | ESHB (UCITS SMH), bo NVDA ~20% | Skoncentrowane |
| Direct stockpicking | NVDA, AVGO, TSM, ASML | Wymaga thesis i monitorowania |
| Tier 2-3 (data center) | VRT, ANET, CEG — przez US broker | Trudno przez UCITS |
| Energia dla AI | Constellation Energy (CEG), NextEra, Cameco | Pośredni beneficjent |
| AI software | WTAI, XAIX (UCITS) | Mix chip + software AI |
Co śledzić, żeby wiedzieć, gdzie jesteśmy w cyklu AI
- NVDA earnings (kwartalne) — guidance forward. Jeśli przestaną podnosić — ostrzeżenie.
- Hyperscaler CAPEX guidance — MSFT, GOOG, AMZN, META quarterly. Jeśli ścinają — to sygnał.
- TSMC capacity utilization — szczególnie CoWoS.
- HBM pricing — TrendForce raporty. Spadające ceny = nadpodaż.
- Data center energy demand — EIA, IEA raporty. Spadek = sygnał recesji AI.
- Liczba GPU rezerwacji — Meta H100 350 000, Microsoft 480 000... gdy te liczby przestaną rosnąć, mamy szczyt.
Podsumowanie
- Era AI compute to strukturalna rewolucja, nie hype — $200+ mld rocznego CAPEX hyperscalerów to fizyczne maszyny.
- NVIDIA dominuje ~80% rynku AI GPU dzięki CUDA, NVLink i tempu iteracji.
- HBM (Hynix, Samsung, Micron) to wąskie gardło — kto produkuje, ten zarabia.
- Tier 2 beneficjenci: SMCI (serwery), VRT (cooling), ANET (networking), CEG (energia nuklearna).
- Ryzyko #1: custom ASIC hyperscalerów może zatrzymać dominację NVDA na inference.
- Najprostsza ekspozycja dla Polaka: ETF CHIP / ESHB. Direct NVDA wymaga aktywnego monitorowania.